I denna artikel tänker jag ge er som inte är bekanta med Event Sourcing en liten annan syn på en applikations tillstånd och hur man lagrar och läser information. Är du redan är bekant med Event Sourcing hoppas jag ändå att du kan ta med dig något från denna läsning.
Låt oss titta på grundkonceptet inom Event Sourcing!
Grundkonceptet
Grundidén med Event Sourcing är att man lagrar data som en serie av händelser (ofta kallad “Events”). Dessa händelser kan inte i efterhand ändras, de är därför immutable. Ni kan tänka er att det är som en logg eller en journal av saker som hänt. Loggar och journaler ändrar man inte på i efterhand, utan man lägger endast till ny information. Det är även sant inom Event Sourcing och det kallas för “append only”.
Om vi slår ihop allt detta till en konkret mening så är Event Sourcing i sin grund “An immutable, append only, stream of events”.

För att få en komplett bild av en patients tillstånd så måste läkaren titta igenom alla händelser i journalen. Samma taktik används i Event Sourcing. För att läsa upp applikationens tillstånd så tittar vi på alla events i ordning och först när vi når det senaste eventet har vi fått en korrekt bild, vilket ofta är den bild som man ser lagrad i en traditionell databas, t.ex en SQL-databas.
Att läsa upp applikationens tillstånd innebär rent konkret, och kodtekniskt, att varje event appliceras via en eventhanterare. Jag kommer i denna artikel att visa kodsnuttar från en applikation som hanterar en fruktkorg. Det känns som en domän som är greppbar och enkel att komma på mer eller mindre vettiga krav för. Här nedan är en så kallad event hanterare för händelsen att ett äpple eller päron har lagts till i vår fruktkorg.
private void Apply(AppleAddedEvent e)
{
_things["apples"].Add(e.Id);
_weights.Add(e.Id, e.Weight);
}
private void Apply(PearAddedEvent e)
{
_things["pears"].Add(e.Id);
_weights.Add(e.Id, e.Weight);
}
Med denna stil får du ett bra fokus på vad som ska göras givet att någonting sker. Det blir enklare att hålla nere komplexiteten på affärslogik och tillståndsförändring eftersom du bara behöver fokusera på en förändring. Jag säger inte att eventhanterare inte kan bli komplexa, det jag säger är att de blir fokuserade och avgränsade vilket gör det enklare att hålla nere komplexiteten.
Projektioner och läsmodeller
Kodexemplet här ovanför ligger i en klass vid namn “CurrentThings”. Denna klass har till uppgift att ge svaret på vilka saker som just nu ligger i din fruktkorg samt innehållets totala vikt. Här spelar det ingen roll vilken typ av äpple som ligger i korgen, vilka färger frukterna har eller om de är färska eller ruttna. Detta kallas ofta för en projicering, eller “projection” på engelska. Är du insatt i DDD/CQRS/CQS är det sannolikt att dina läsmodeller är projektioner.
En projicering är en specifik synvinkel på eventströmmen (journalen). Events “spelas upp”, i ordning, genom dessa eventhanterare och projiceringens tillstånd tar form och solidifieras när sista eventet har applicerats.
Nedan följer en annan användning av eventströmmen. Om du vill veta om en specifik frukt är ätbar så kan du skapa en projicering som lyssnar på fruktevents och i händelse av att frukten har ruttnat så är den inte ätbar, i alla andra fall är den det. Detta är såklart ett förenklat exempel, men du förstår säkert konceptet?
private void Apply(IDomainEvent e)
{
Value = e switch
{
FruitDecomposedEvent => false,
_ => Value
};
}
Domänaggregat
I Domän Driven Design pratar man ofta om aggregatrötter. Dessa är också projiceringar av events! I detta fall med en frukkorg är korgen en aggregatrot. Vi kallar den för Basket. En korg kan endast skapas från en eventström (eller den tomma strömmen) via en fabriksmetod “Replay”. Av namnet att döma spelar vi upp alla events som funktionen anropas med. Replay delegerar vidare till respektive Apply-funktion som applicerar eventet och dess data på aggregatet.
Den uppmärksamme ser att vi har två publika metoder, AddFruit och GrabAThing. Dessa metoder innehåller domänlogik. Än mer intressant är att dessa metoder skapar events och kör dessa genom respektive Apply-metod; samma tillvägagångssätt som i Replay-metoden. Samma sätt att göra tillståndsförändringar alltså. Detta är viktigt. Om någon annan metod än Apply gör tillståndsförändringar kommer dessa gå förlorade när du läser upp aggregatet nästa gång.
// Viss kod är borttagen för läsbarhetens skull
public class Basket
{
public static Basket Replay(ICollection<IDomainEvent> events)
{
var basket = new Basket();
foreach (var e in events)
{
basket.Apply((dynamic)e);
}
return basket;
}
public void AddFruit(IFruit fruit)
{
EnsureThatFruitNotAlreadyAdded(fruit);
IDomainEvent ev = fruit switch
{
Apple => new AppleAddedEvent(fruit.Id, fruit.Weight, fruit.FruitCondition),
Pear => new PearAddedEvent(fruit.Id, fruit.Weight, fruit.FruitCondition),
_ => new UnknownFruitAddedEvent(fruit.Id, fruit.Weight, fruit.FruitCondition)
};
_events.Add(ev);
Apply((dynamic)ev);
}
public void GrabAThing(string thingId)
{
EnsureThatThingIsInTheBasket(thingId);
var theThing = _things.Single(x => x.Id == thingId);
var ev = theThing is IFruit ? new FruitGrabbedEvent(thingId) : new ThingGrabbedEvent(thingId);
_events.Add(ev);
Apply((dynamic)ev);
}
private void Apply(AppleAddedEvent e)
{
_things.Add(new Apple(e.Id, e.Weight, e.FruitCondition));
}
private void Apply(PearAddedEvent e)
{
_things.Add(new Pear(e.Id, e.Weight, e.FruitCondition));
}
private void Apply(ThingGrabbedEvent e)
{
var theThing = _things.SingleOrDefault(x => x.Id == e.Id);
_things.Remove(theThing);
}
private void EnsureThatFruitNotAlreadyAdded(IFruit fruit)
{
if (_things.Any(x => x.Id == fruit.Id))
{
throw new System.Exception("Fruit already added...");
}
}
private void EnsureThatThingIsInTheBasket(string thingId)
{
var theThing = _things.SingleOrDefault(x => x.Id == thingId);
if (theThing is null)
{
throw new System.Exception("no no, someone already took it out");
}
}
}
Ingen data tas bort
Med projiceringar kan du se på din eventström på många olika sätt och svara på många olika frågor. Frågor som inte alls behöver ha varit kända när systemet byggdes. Du kan svara på frågan “vilka äpplen låg i korgen den 3e april 2018 kl 08:30”. Om detta inte var ett ursprungligt krav och du lagrade informationen i en SQL-databas hade det blivit svårt att ge svaret på den frågan. Hemligheten ligger i att ingen data tas bort, någonsin. Event Sourcing är en, som nämnt, “append only, immutable stream of events”. Det finns inga DELETE-statements. Det finns inga UPDATE-statements. Den senare är faktiskt en implicit DELETE då vi skriver över föregående värden med nya värden, således är det en DELETE på de gamla värdena.
Detta är oerhört kraftfullt!
Hantering av Event Streams
I Event sourcing lagras data som en serie av events, så kallade strömmar (streams på engelska). Det är från en eller flera strömmar som du ställer frågor till. Du har full frihet i vilka strömmar du väljer att ha. I teorin kan du lagra alla events i en global ström och ha denna ström som utgångspunkt när du projicerar. Problemet med detta sätt är att strömmen snabbt växer sig lång. Kom ihåg att du läser eventströmmen från början till slut och skulle det ligga 1 miljon events så måste 1 miljon events hanteras i dina projektioner.
Att skapa en ström är en billig operation i de olika eventdatabaserna och därför kan, och bör du, tänka på hur du vill partitionera dina strömmar. En ofta rekommenderad partitionering för dina domänentiteter är en ström per instans/entitet. Exempel på namn för vår Basket-entitet kan vara “basket-1”, “basket-2” eller “basket-42”. Numret är som ni förstår entitetens ID. Dessa strömmar kan med fördel alltså skapas dynamiskt vid behov. Fördelen med detta är att stömmarna blir små, i förhållande till en “one for all” global ström, och därför mycket mer effektiv att hämta events från.
Strömmar kan också nyttjas till att lagra events till en eller flera läsmodeller. Man kan tänka sig att man har en renodlad ström av events för äpplen. Det handlar ofta om kategoriseringar av events - något som t.ex EventStoreDB kan bygga upp åt dig automatiskt.
Oavsett hur du partitionerar dina strömmar kan du inte alltid skydda dig från långa eventströmmar. Hur hanterar vi ett aggregat som har 1 miljon events? Eller 100 miljoner? Enkelt uttryckt kan vi nyttja en ny eventström för att lagra något man kallar för “snapshots”.
Snapshots
En snapshot är en ögonblicksbild av ett tillstånd. Säg att du har spelat upp 100 miljoner händelser och har nuvarande tillstånd. Nu kan du skapa en ny ström och dumpa nuvarande tillstånd dit. Nästa gång applikationen behöver läsa upp dessa 100 miljoner events behöver den bara titta i snapshot-strömmen, och med snapshoten som utgångsläge hämta alla nya events som appliceras över snapshotten. Processen kan upprepa sig om eventströmmen växer sig stor igen, då tas en ny snapshot ut som blir den nya utgångspunkten. Se bild nedan.
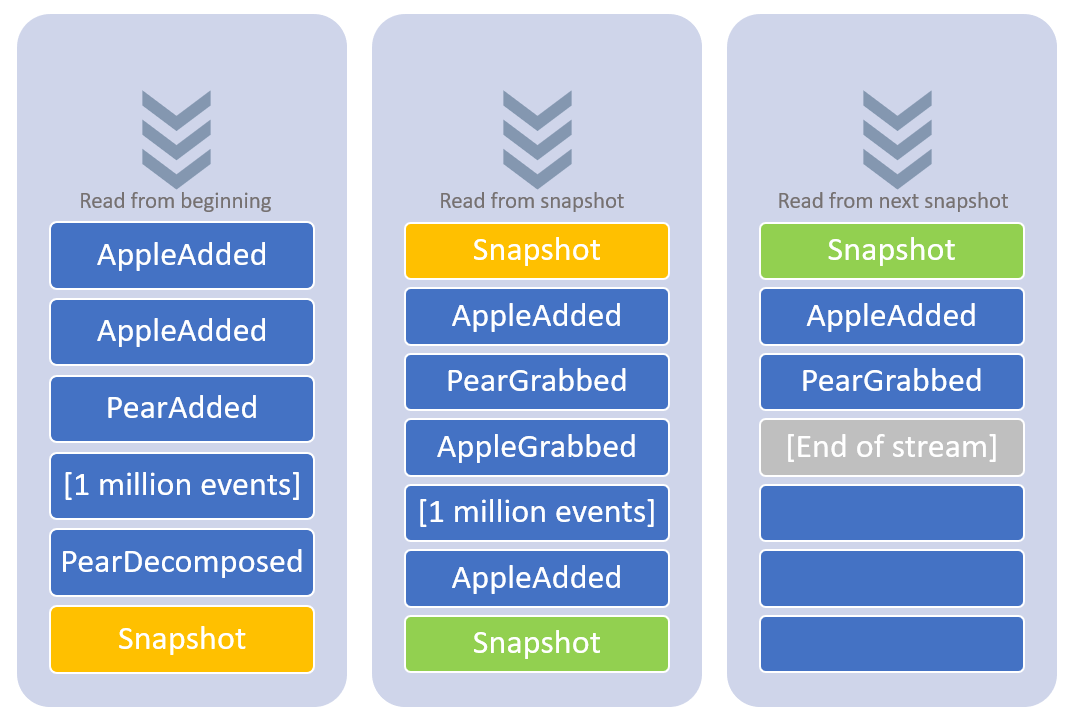
Snapshots i andra lagringsmedium
En snapshot behöver inte finnas i din event store. Den kan finnas som en 3NF-modell i en SQL-databas, ett dokument i MongoDB eller finnas i ElasticSearch. För att nämna några exempel. Poängen är att en snapshot är en nubild av en eventström och den bilden kan se ut och ligga vart som helst.
Sammanfattning
En av de stora fördelarna med Event Sourcing är möjligheten att ge svar på vilken fråga som helst. Om verksamheten efter 5 år kommer med frågan hur det såg ut vid en viss tidpunkt, hur många äpplen som någonsin funnits i korgen, hur många päron som ruttnat i korgen, etc. Så kan vi svara på det. Det är inte alla som kan. Givetvis måste eventsen innehålla data för att kunna ge svaren. Applikationen kommer inte kunna svara på meningen med livet bara för att det är Event Sourcing.
Givetvis finns det nackdelar också. Eller en annan sida av myntet. Event sourcing skiljer sig ganska mycket från den typiska applikationen. Event sourcing gör sig också väl i system som anammar mönster/designs som CQRS och DDD. Det är en tröskel att ta sig över, ofta en relativt hög tröskel. Det medför givetvis en risk för projektet.
Uppsidan är däremot stor. Har du läst hit och blivit nyfiken så kan jag rekommendera att se olika talks som t.ex. denna med Greg Young.
Med det tackar jag för mig.

Lämna en kommentar